
misc其实是英文miscellaneous的前四个字母,杂项、混合体、大杂烩的意思。是CTF比赛中最杂乱包罗万象的一个类别,也是最有趣的一个类别。
001 this_is_flag
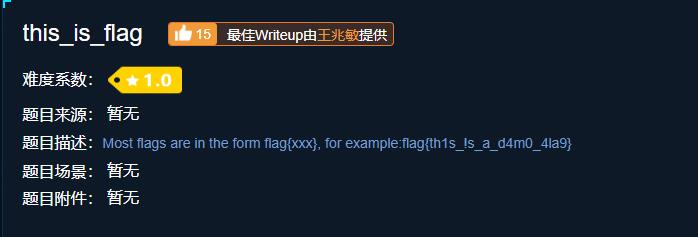
题目中直接给出flag,ctrl+c ctrl+v,通过
flag{th1s_!s_a_d4m0_4la9}002 pdf
题目明确指向要下载附件,下载发现是pdf文件,windows下可以用网站转换成Word,把图片拿开就能看到了。kali可以用pdftotext*.pdf *.txt转换(转换成Word也行)
flag{security_through_obscurity} pdftotext
在命令行中输入
pdftotext [选项] [文件PDF文件] [文本]- -opw 密码指定PDF文件所有者密码。提供这将绕过所有的安全限制。
- -v输出版权和版本信息。
- -h 输出有用的信息。(-help 和–help是相当的)
BUGS
一些PDF文件内容字体的编码不明晰,所以无法从中读取信息到文本文件。
出错代码
Xpdf出错时代码的含义
- 0 正常
- 1 打开PDF出错
- 2 打开输出文件出错
- 3 PDF权限相关错误
- 99 其它错误
003与佛伦禅
First
打开文件后,是一段繁体的佛经,百度"与佛论禅"后有一个网页,通过阅读"普度众生"知道,复制过来的必须是繁体,并且要在前面加上"佛曰:",解码后得到
MzkuM3gvMUAwnzuvn3cgozMlMTuvqzAenJchMUAeqzWenzEmLJW9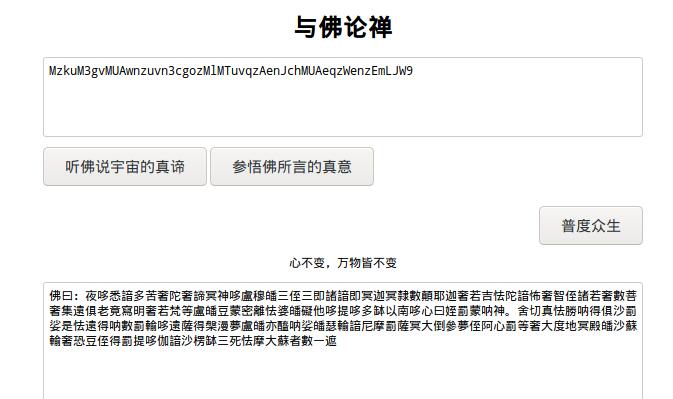
看起来像是base64加密,解密后是乱码,然后题干中说道学到了十三掌,用rot13解密后再base64解密得到答案。

echo -n "str" | base64 -d将字符串str编码为base64字符串输出
- base64 -d <\br>
从标准输入中读取已经进行base64编码的内容,解码输出- echo -n "str" | base64
将字符串str编码为base64字符串输出。- echo "str" | base64
将字符串str+换行 编码为base64字符串输出
设字符串长度为$n$,base64加密后长度为$\lceil \frac{n}{3} \times 4 \rceil$,$\lceil x \rceil$表示向上取整
004give_you_flag
补上二维码的三个点直接就能扫出来,这种点帮助识别二维码的位置,三个点可以定位出二维码的矩形范围,确定了高度、宽度和角度。
005坚持60s
- 第一步:jar包解压
JAR文件是一种归档文件,以ZIP格式构建,以.jar为文件扩展名。用户可以使用JDK自带的jar命令创建或提取JAR文件。也可以使用其他zip压缩工具,不过压缩时zip文件头里的条目顺序很重要,因为Manifest文件常需放在首位。JAR文件内的文件名是Unicode文本。unzip -qo 9dc125bf1b84478cb14813d9bed6470c.jar -d temp - 第二步:反编译
通过jad反编译出字符
jad -o -r -sjava -dsrc 'cn/**/*.class' > /dev/null 2>&1- 第三步:通过
grep匹配"flag"grep "flag" . -rn - 第四步:显示匹配到的字符字符串
strings PlaneGameFrame.class | grep flag后面有"="字符,是base64,解密就能得到flag了
echo "RGFqaURhbGlfSmlud2FuQ2hpamk=" | base64 -d
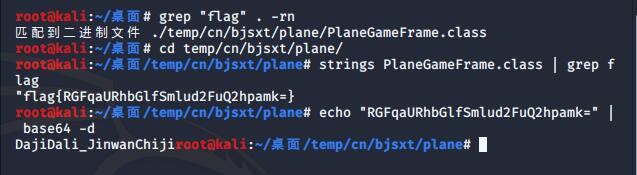
最后得到答案
006 gif
查看发现有104张jpg黑白图片,有点像2进制里的0和1,$\frac{104}{8}=13$也就是说有13个数字,编写python脚本,利用PIL库能够迅速转化。
from PIL import Image
def getflag(seq1):
a1 = ""
for i in range(104//8):
s1 = seq1[:8]
seq1 = seq1[8:]
i1 = int(s1,2)
a1 += chr(i1)
return a1
def main():
seq1=""
seq2=""
for i in range(104):
filename = "gif/"+str(i)+".jpg"
img = Image.open(filename)
clrs = img.getcolors()
if sum(clrs[0][5])>400:
seq1+="0"
seq2+="1"
else:
seq1+="1"
seq2+="0"
print(getflag(seq1))
print(getflag(seq2))
if __name__ == "__main__":
main()得到flag,flag{FuN_giF}
007 掀桌子
一串字符串。看起来像是16进制,转换成十进制,都不在ASCII范围内,并且数与数之间相差不大。
def main():
s="c8e9aca0c6f2e5f3e8c4efe7a1a0d4e8e5a0e6ece1e7a0e9f3baa0e8eafae3f9e4eafae2eae4e3eaebfaebe3f5e7e9f3e4e3e8eaf9eaf3e2e4e6f2"
while s:
tmp=s[:2]
a=int(str(tmp),16)
print(a,end=" ")
s=s[2:]
if __name__ == "__main__":
main()
可能是凯撒移位,然后栅栏密码,但是肯定是先转化到ASCII范围之内。
def main():
seq = "c8e9aca0c6f2e5f3e8c4efe7a1a0d4e8e5a0e6ece1e7a0e9f3baa0e8eafae3f9e4eafae2eae4e3eaebfaebe3f5e7e9f3e4e3e8eaf9eaf3e2e4e6f2"
for i in range(100, 500):
flag = ""
s = seq
while s:
tmp = s[:2]
ch = chr(int(tmp, 16)-i)
s = s[2:]
flag += ch
if all(ord(c) < 127 and ord(c) > 31 for c in flag):
print(flag)
if __name__ == "__main__":
main()然后Hi, FreshDog! The flag is: hjzcydjzbjdcjkzkcugisdchjyjsbdfr
008 掀桌子
解压rar文件,只能解压出一个txt文件,里面并没有我们想要的东西,使用bless打开rar文件,我们要的是文件块而不是子块,于是更改7A为74,成功解压。查看文件类型file发现是一个.gif图片,使用stegsolve帧功能模块,得到两张不同的帧图片,调节颜色,得到两张残缺的二维码图片,合并补齐后,扫一扫即可。


StegSolve的安装参考这个博客。
009 base64stego
如来十三掌的最后一步,即BASE64解密,在压缩软件里打开这个文件发现有很长的BASE64编码。
https://www.tr0y.wang/2017/06/14/Base64steg/
...查看writeup后,涉及到BASE64隐写
010 功夫再高也怕菜刀
第一步:查看pacp包中的隐藏文件
binwalk acfff53ce3fa4e2bbe8654284dfc18e1.pcapng使用foremost分离出一个有密码的压缩包,压缩包里的文件名为“flag.txt”,所以剩下的就是找解压密码。
用“wireshark”打开流量包,Ctrl+F搜索“flag.txt”,选择“字符串”和“分组字节流”然后点查找,点几下后发现一张名为“6666.jpg”的图片。在图片名那行右键“追踪流-TCP流”,把整个对话保存为文件。
用文本编辑器,编辑导出的文件,查找并删除第一个jpg文件头(FFD8)和最后一个文件尾(FFD9)之外的字符串,剩下的全是十六进制字符串。然后把十六进制保存为图片,我用的“010 Editor”,打开后新建空白文件,复制图片十六进制字符串到粘贴板,点击菜单栏“Edit-Paste From-Paste From Hex Text”,然后保存为图片就行了。
解压密码
Th1s_1s_p4sswd_!!!用图片中的密码去解压能够得到flag
flag{3OpWdJ-JP6FzK-koCMAK-VkfWBq-75Un2z}011 ext3
root模式下使用mount linux /mnt命令将linux光盘挂载在mnt目录下,切换到mnt目录,使用find | grep "flag",再使用cat O7avZhikgKgbF/flag.txt命令即可对flag内容进行读取,发现是一个base64编码,解密后得到flag.

012 stegano
将pdf文件导出成txt
BABA BBB BA BBA ABA AB B AAB ABAA AB B AA BBB BA AAA BBAABB AABA ABAA AB BBA BBBAAA ABBBB BA AAAB ABBBB AAAAA ABBBB BAAA ABAA AAABB BB AAABB AAAAA AAAAA AAAAB BBA AAABB莫斯密码
用ailx10的脚本
dict1 = {'A': '.',
'B': '-',
' ': '/'
};
dict2 = {'.-': 'a',
'-...': 'b',
'-.-.': 'c',
'-..':'d',
'.':'e',
'..-.':'f',
'--.': 'g',
'....': 'h',
'..': 'i',
'.---':'j',
'-.-': 'k',
'.-..': 'l',
'--': 'm',
'-.': 'n',
'---': 'o',
'.--.': 'p',
'--.-': 'q',
'.-.': 'r',
'...': 's',
'-': 't',
'..-': 'u',
'...-': 'v',
'.--': 'w',
'-..-': 'x',
'-.--': 'y',
'--..': 'z',
'.----': '1',
'..---': '2',
'...--': '3',
'....-': '4',
'.....': '5',
'-....': '6',
'--...': '7',
'---..': '8',
'----.': '9',
'-----': '0',
'--..--': ',',
'---...': ':',
'/': ' '
};
enc_str0="BABA BBB BA BBA ABA AB B AAB ABAA AB B AA BBB BA AAA BBAABB AABA ABAA AB BBA BBBAAA ABBBB BA AAAB ABBBB AAAAA ABBBB BAAA ABAA AAABB BB AAABB AAAAA AAAAA AAAAB BBA AAABB"
enc_str1=""
dec_str=""
for i in enc_str0:
enc_str1+=dict1[i]
enc_str1=enc_str1.split("/")
print(enc_str1)
for i in enc_str1:
dec_str += dict2[i]
print(dec_str)


0 条评论