
一、GPU基本模型
0.1 APOD开发模型
即:Assess, Parallelize, Optimize, Deploy
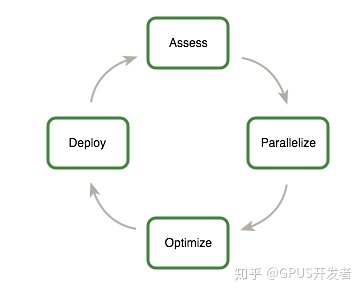
【CUDA优化的冷知识】什么是APOD开发模型? - 知乎 (zhihu.com)
1.1 nvcc
- nvcc就是CUDA的编译器,CUDA程序有两种代码,在CPU上的host代码和在GPU上的device代码。
1.1.1 常用命令
-
nvcc单文件编译
GPU设备的应用兼容性和CPU明显不同,CPU每一代指令集一般都兼容上一代指令集,所以已发布的应用可以运行在新一代的CPU硬件上,但GPU新一代指令集不兼容上一代的指令集。GPU使用virtual architectures来保证应用层兼容性(PTX可以看做虚拟的GPU架构,PTX是文本指令)。
指定的虚拟架构版本(PTX),要小于等于生成native二进制代码时候的版本。避免无法从PTX进行jit或者aot生成实际指令。
不指定会使用默认的计算能力。不一定是5.3,如果可能,尽量指定。以及,默认的指定会保留一份PTX。一般够用(除非你在11.x的toolkit上使用Kepler的卡,默认保留的Maxwell的PTX不能向下兼容)。
所以在执行编译命令是要指定架构,否则会出现单个文件不运行CUDA,GPU部分的代码,也就是你的GPU算力,可以查看显卡算力列表,如我的是GeForce GTX 960M,则对应的是5.0,则写成sm_50或者compute_50
nvcc .\cuda.cu -o cuda -arch compute_50 -Wno-deprecated-gpu-targets 输入文件名 输出文件名 指定GPU体系结构 忽略compute_50所带来的警告(未来可能会移除对compute_50的支持,这里也可以写为sm_50) -
nvcc多文件编译
nvcc --device-c hello_from_gpu.cu -o hello_from_gpu.o nvcc hello_cuda02-test.cu hello_from_gpu.o -o hello_cuda_multi_file--device-c这个选项是编译.o文件所需要的。可以直接理解成CPU上的-c, 因为CUDA 3.2之前的问题,导致了rdc的出现(3.2以前的CUDA要求跨文件隔离kernel和符号),所以-c变成了-rdc=true -c, 最终变成了-dc(--device-c)
-
makefile执行nvcc命令
TEST_SOURCE = hello_cuda02-test.cu TARGETBIN := ./hello_cuda_multi_file CC = /usr/local/cuda/bin/nvcc $(TARGETBIN):$(TEST_SOURCE) hello_from_gpu.o $(CC) $(TEST_SOURCE) hello_from_gpu.o -o $(TARGETBIN) hello_from_gpu.o:hello_from_gpu.cu $(CC) --device-c hello_from_gpu.cu -o hello_from_gpu.o .PHONY:clean clean: -rm -rf $(TARGETBIN) -rm -rf *.o
nvprof
cuDeviceGetAttribute获得各个属性,是cudaGetDeviceProperties()的底层调用。而这个是CUDA Runtime底层初始化的时候自动进行的(用来获取你的设备信息,适配一些东西,例如决定加载哪个版本的设备代码(如果你为多种设备的计算能力编译的话), 等等),是自动的。无需操心。
除了. LaunchKernel那行(这个是cudaLaunchKernel或者<<<>>>, 菱形操作符会被编译为前者),或者cudaDeviceSynchronize()这行,其他都可以不关心。
二、CUDA一些概念
2.1 术语
Host:CPU和内存;
Device:GPU和显存;
CUDA中计算分为两部分,串行部分在Host上执行,即CPU,而并行部分在Device上执行,即GPU。
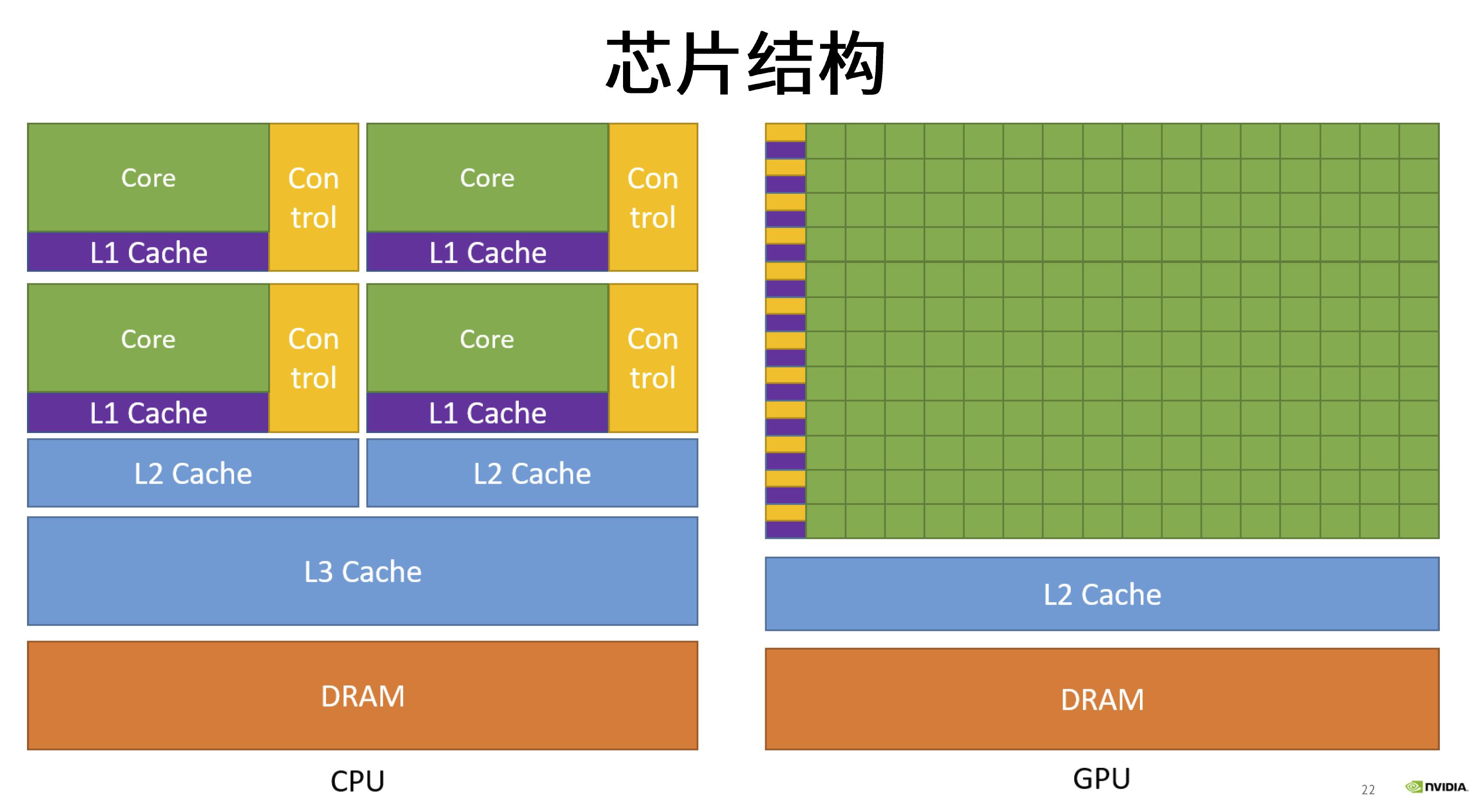
2.2 显卡硬件架构:SM、SP、Warp
具体到nvidia硬件架构上,有以下两个重要概念:
SP(streaming processor):最基本的处理单元,也称为CUDA core。最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
SM(streaming multiprocessor):多个SP加上其他的一些资源组成一个SM,也叫GPU大核,其他资源如:warp scheduler,register,shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。如下图是一个SM的基本组成,其中每个绿色小块代表一个SP。
一个SM里有几个CUDA core,这个不能通过API查询。只能检测计算能力后,写死。(例如7.5的计算能力,对应64个/SM)。而计算能力可以通过cudaGetDeviceProperties()获得,这样你再硬编码一个计算能力和SP数量/SM的对应关系的表格,就可以得到你的卡的每SM的SP个数了。这也是deviceQuery例子的做法,无法直接通过API得到
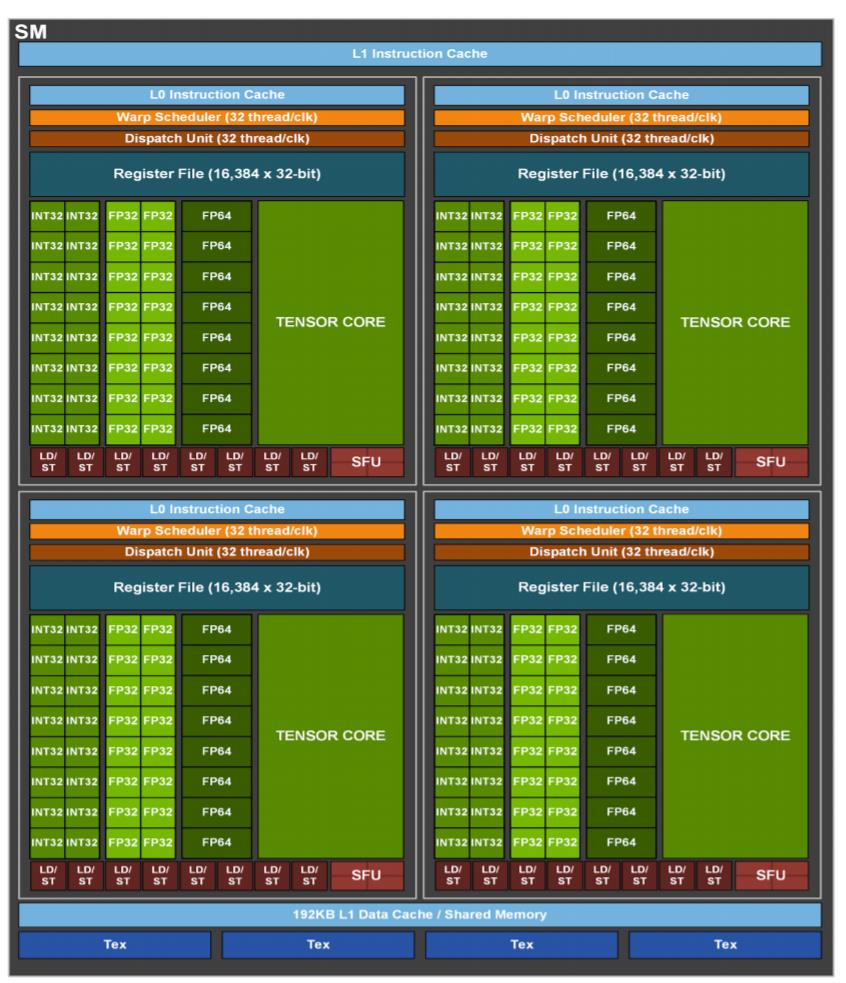
每个SM包含的SP数量依据GPU架构而不同,Fermi架构GF100是32个,GF10X是48个,Kepler架构都是192个,Maxwell都是128个。当一个kernel启动后,thread会被分配到很多SM中执行。大量的thread可能会被分配到不同的SM,但是同一个block中的thread必然在同一个SM中并行执行。
Warp调度
一个SP可以执行一个thread,但是实际上并不是所有的thread能够在同一时刻执行。Nvidia把32个threads组成一个warp,warp是调度和运行的基本单元。warp中所有threads并行的执行相同的指令。一个warp需要占用一个SM运行,多个warps需要轮流进入SM。由SM的硬件warp scheduler负责调度。目前每个warp包含32个threads(Nvidia保留修改数量的权利)。所以,一个GPU上resident thread最多只有 SM*warp个。
同一个warp中的thread可以以任意顺序执行,active warps被SM资源限制。当一个warp空闲时,SM就可以调度驻留在该SM中另一个可用warp。在并发的warp之间切换是没什么消耗的,因为硬件资源早就被分配到所有thread和block,所以新调度的warp的状态已经存储在SM中了。
每个SM有一个32位register集合放在register file中,还有固定数量的shared memory,这些资源都被thread瓜分了,由于资源是有限的,所以,如果thread比较多,那么每个thread占用资源就叫少,thread较少,占用资源就较多,这需要根据自己的要求作出一个平衡。
改成33就会分配两个warp, 超出哪怕1个线程,也会分配一个warp(浪费31/32的潜在执行能力)。
2.3 软件架构:Kernel、Grid、Block
我们如何调用GPU上的线程实现我们的算法,则是通过Kernel实现的。在GPU上调用的函数成为CUDA核函数(Kernel function),核函数会被GPU上的多个线程执行。我们可以通过如下方式来定义一个kernel:
func_name<<<grid, block>>>(param1, param2, param3....);这里的grid与block是CUDA的线程组织方式,具体如下图所示:
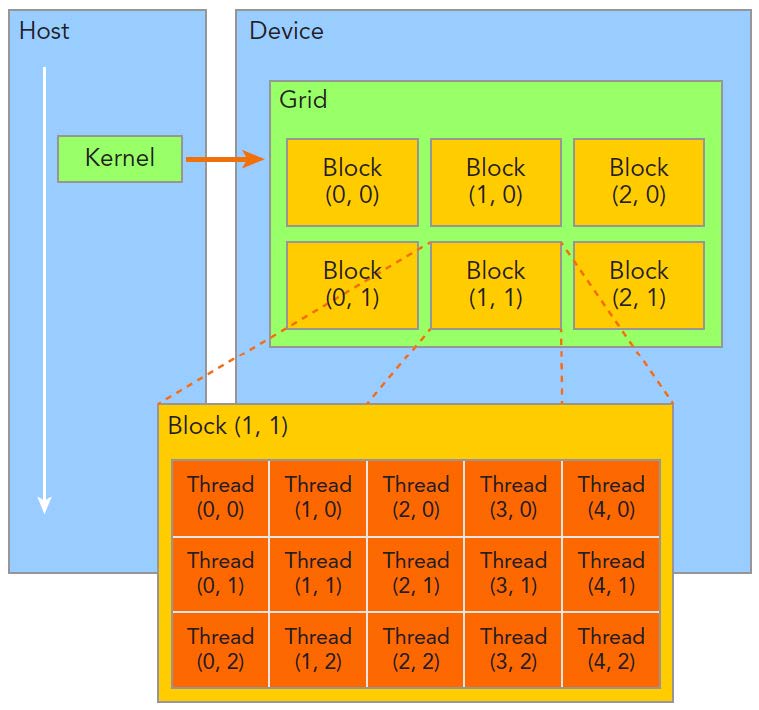
Grid:由一个单独的kernel启动的所有线程组成一个grid,grid中所有线程共享global memory。Grid由很多Block组成,可以是一维二维或三维。
Block:一个grid由许多block组成,block由许多线程组成,同样可以有一维、二维或者三维。block内部的多个线程可以同步(synchronize),可访问共享内存(share memory)。
CUDA中可以创建的网格数量跟GPU的计算能力有关,可创建的Grid、Block和Thread的最大数量如下所示:
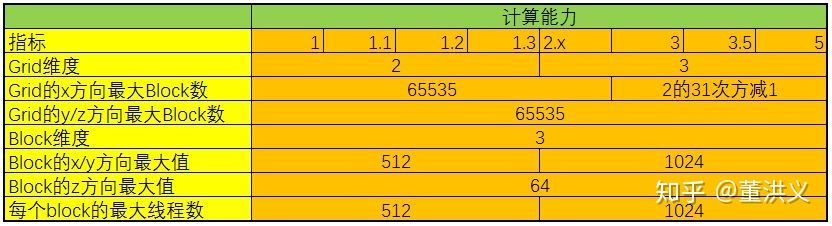
所有CUDA kernel的启动都是异步的,当CUDA kernel被调用时,控制权会立即返回给CPU。在分配Grid、Block大小时,我们可以遵循这几点原则:
- 保证block中thread数目是32的倍数。这是因为同一个block必须在一个SM内,而SM的Warp调度是32个线程一组进行的。
- 避免block太小:每个blcok最少128或256个thread。
- 根据kernel需要的资源调整block,多做实验来挖掘最佳配置。
- 保证block的数目远大于SM的数目。
三、CUDA程序编写
3.1 三个函数
| 函数名(重点是前面的修饰符) | 执行位置 | 调用位置 |
|---|---|---|
| __device__ float DeviceFunc() | device | device |
| __global__ void KernelFunc() | device | host & device(arch>3.0) |
| __host__ float HostFunc() | host | host |
__global__定义一个kernel函数,入口函数,CPU上调用,GPU上执行,必须返回void。
调用核函数的方式:KernelFunc<<<block num, thread num>>>(参数1,……),三个尖括号里面用于指定block数量和thread数量,这样我们的总线程数=block*thread
3.2 CUDA并行计算基础
3.2.1 CUDA线程层次
CUDA编程是一个多线程编程,数个线程(Thread)组成一个线程块(Block),所有线程块组成一个线程网格(Grid),如下图所示:
图中的线程块,以及线程块中的线程,是按照2维的方式排布的。实际上,CUDA编程模型允许使用1维、2维、3维三种方式来排布。另外,即使线程块使用的是1维排布,线程块中的线程也不一定要按照1维排,而是可以任意排布。
Thread:sequential execution unit,所有线程执行相同的核函数,并行执行。
Thread Block:a group of threads,执行在一个Streaming Multiprocessor(SM),同一个Block中的线程可以协作。
Thread Grid:a collection of thread blocks,一个Grid中的Blockj可以在多个SM中执行。
软件和硬件对应:

3.2.2 CUDA线程索引
block、thread可以是一维、二维或三维,因此x,y,z分别代表对应的维度。
threadIdx.[x y z]:执行当前核函数的线程在block中的索引值。
blockIdx.[x y z]:执行当前核函数的线程所在的block在grid中的索引值。
gridDim.[x y z]:表示一个grid中包含多少个block。
blockDIm.[x y z]:表示一个block中包含多少个线程。
最后两个值,就是<<<>>>中的值,gridDim*blockDim是总线程个数。
上面四个变量可以在核函数中直接使用。
int index = threadIdx.x + blockIdx.x * blockDim.x 计算当前线程的总索引值。
3.2.3 CUDA线程分配

当调用线程超过32个时,就会用重新再去执行(比mpi智能多了),用一个for或者while循环,每次变换这些线程们的坐标。直到坐标范围能覆盖所有要干的事情。
block中有多个Warp,因此block中的线程个数一定是32的倍数,如果你指定31,也要花费一个Wrap。
N=100000; // 总计算量
block_size = 128; // block中的线程数
grid_size = (N+block_size -1)/block_size; //grid中的block数x,y,z三个维度如果我们没有设置y和z,那么默认为1
3.3.4 CUDA Thread Indexing
-
1D grid of 1D blocks
__device__ int getGlobalIdx_1D_1D(){ return blockIdx.x*blockDim.x+threadIdx.x; } -
1D grid of 2D blocks
__device__ int getGlobalIdx_1D_3D() { return blockIdx.x * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x; } -
1D grid of 3D blocks
__device__ int getGlobalIdx_1D_3D() { return blockIdx.x * blockDim.x * blockDim.y * blockDim.z + threadIdx.z blockDim.y * blockDim.x + threadIdx.y * blockDim.x + threadIdx.x; } -
2D grid of 1D blocks
__device__ int getGlobalIdx_2D_1D() { int blockId = blockIdx.y * gridDim.x + blockIdx.x; int threadId = blockId * blockDim.x + threadIdx.x; return threadId; } -
2D grid of 2D blocks
__device__ int getGlobalIdx_2D_2D() { int blockId = blockIdx.x + blockIdx.y * gridDim.x; int threadId = blockId * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x; return threadId; } -
2D grid of 3D blocks
__device__ int getGlobalIdx_2D_3D() { int blockId = blockIdx.x + blockIdx.y * gridDim.x; int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x) + threadIdx.x; return threadId; } -
3D grid of 1D blocks
__device__ int getGlobalIdx_3D_1D() { int blockId = blockIdx.x + blockIdx.y * gridDim.x + gridDim.x * gridDim.y * blockIdx.z; int threadId = blockId * blockDim.x + threadIdx.x; return threadId; } -
3D grid of 2D blocks
__device__ int getGlobalIdx_3D_2D() { int blockId = blockIdx.x + blockIdx.y * gridDim.x + gridDim.x * gridDim.y * blockIdx.z; int threadId = blockId * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x; return threadId; } -
3D grid of 3D blocks
__device__ int getGlobalIdx_3D_3D() { int blockId = blockIdx.x + blockIdx.y * gridDim.x + gridDim.x * gridDim.y * blockIdx.z; int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x) + threadIdx.x; return threadId; }
四、sobel边缘检测、矩阵相乘和转化灰度图
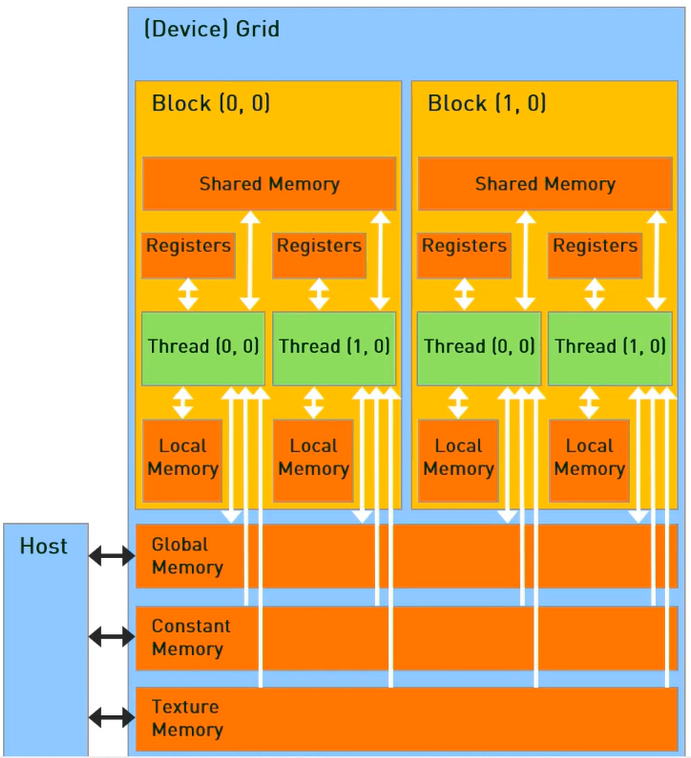
4.1 GPU的存储单元
每一个线程可以:
读/写每一个线程registers;
读/写每一个线程local memory;
读/写每一个block shared memory;
读/写每一个grid global memory;
只读每一个grid constant memory;
只读每一个grid texture memory。
cuda里把连续128bit的数据从global memery先复制到 share memory再复制到register, 和先从gmem到reg再到smem,速度有差别么?
--直接复制到shared memory, 不使用特殊的写法,直接用等号的形式,例如:__shared__ int kachi[...];
kachi[xxx] = ptr[xxxx]; (其中ptr是一个指向显存/global memory某区域的指针)。
这种写法实际上编译器,“会自动通过寄存器中转的”,和你手工:
tmp = ptr[xxxx];
dog[xxx] = tmp;
并无本质区别。因为这两个是一回事,只是节省了你的中间变量的写法,实际代码生成是一样的,所以不会有任何差别。
4.2 memory allocation/release
CPU:
- malloc()
- memset()
- free()
gpu:
| 函数 | 形参 | 含义 |
|---|---|---|
| __host __device cudaError_t cudaMalloc ( void** devPtr, size_t size ) | devPtr:指向分配内存size:需要分配的大小 | 在设备上分配内存 |
| __host __device cudaError_t cudaFree ( void* devPtr ) | devPtr:需要释放的设备内存指针 | 释放设备内存 |
| __host__ cudaError_t cudaMemcpy ( void dst, const void src, size_t count, cudaMemcpyKind kind ) | dst:目的地址;src:源地址;count:字节数;kind:方向,包括: cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToDevice, cudaMemcpyDefault | 从src拷贝count个字节到dst |
4.3 sobel边缘检测
4.3.1 基本原理
Sobel边缘检测算法比较简单,实际应用中效率比canny边缘检测效率要高,但是边缘不如Canny检测的准确,然而在很多实际应用的场合,sobel边缘却是首选,Sobel算子是高斯平滑与微分操作的结合体,所以其抗噪声能力很强,用途较多。尤其是在对效率要求较高,而对细纹理不太关系的时候。
使用Sobel算子提取图像边缘分3个步骤:
-
提取X方向的边缘,X方向一阶Sobel边缘检测算法为:
$$
sobel_x=\left[\begin{matrix}
-1&0&1\\
-2&0&2\\
-1&0&1
\end{matrix}\right]
$$ -
提取Y方向的边缘,Y方向一阶Sobel边缘检测算法为:
$$
sobel_y=\left[\begin{matrix}-1&-2&-1\\0&0&0\\1&2&1\end{matrix}\right]
$$ -
综合两个方向的边缘信息得到整幅图像的边缘。
4.3.2 代码
#include <iostream>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
// GPU实现Sobel边缘检测
// x0 x1 x2
// x3 x4 x5
// x6 x7 x8
__global__ void sobel_gpu(unsigned char* in, unsigned char* out, int imgHeight, int imgWidth) {
//通过线程确定处理的像素点
int x = threadIdx.x + blockDim.x * blockIdx.x;
int y = threadIdx.y + blockDim.y * blockIdx.y;
//输出图像的像素点
int index = y * imgWidth + x;
int Gx = 0;
int Gy = 0;
unsigned char x0, x1, x2, x3, x4, x5, x6, x7, x8;
//有界性判断和sobel算法
if (x > 0 && x < imgWidth && y > 0 && y < imgHeight) {
x0 = in[(y - 1) * imgWidth + x - 1];
x1 = in[(y - 1) * imgWidth + x];
x2 = in[(y - 1) * imgWidth + x + 1];
x3 = in[(y)*imgWidth + x - 1];
x4 = in[(y)*imgWidth + x];
x5 = in[(y)*imgWidth + x + 1];
x6 = in[(y + 1) * imgWidth + x - 1];
x7 = in[(y + 1) * imgWidth + x];
x8 = in[(y + 1) * imgWidth + x + 1];
Gx = (x0 + x3 * 2 + x6) - (x2 + x5 * 2 + x8);
Gy = (x0 + x1 * 2 + x2) - (x6 + x7 * 2 + x8);
out[index] = (abs(Gx) + abs(Gy)) / 2;
}
}
// CPU实现Sobel边缘检测
void sobel_cpu(Mat srcImg, Mat dstImg, int imgHeight, int imgWidth) {
int Gx = 0;
int Gy = 0;
for (int i = 1; i < imgHeight - 1; i++) {
uchar* dataUp = srcImg.ptr<uchar>(i - 1);
uchar* data = srcImg.ptr<uchar>(i);
uchar* dataDown = srcImg.ptr<uchar>(i + 1);
uchar* out = dstImg.ptr<uchar>(i);
for (int j = 1; j < imgWidth - 1; j++) {
Gx = (dataUp[j - 1] + 2 * data[j - 1] + dataDown[j - 1]) - (dataUp[j + 1] + 2 * data[j + 1] + dataDown[j + 1]);
Gy = (dataUp[j - 1] + 2 * dataUp[j] + dataUp[j + 1]) - (dataDown[j - 1] + 2 * dataDown[j] + dataDown[j + 1]);
out[j] = (abs(Gx) + abs(Gy)) / 2;
}
}
}
int main() {
//利用opencv的接口读取图片
Mat img = imread("1.jpg", 0);
int imgWidth = img.cols;
int imgHeight = img.rows;
//利用opencv的接口对读入的grayImg进行去噪
Mat gaussImg;
GaussianBlur(img, gaussImg, Size(3, 3), 0, 0, BORDER_DEFAULT);
// CPU结果为dst_cpu, GPU结果为dst_gpu
Mat dst_cpu(imgHeight, imgWidth, CV_8UC1, Scalar(0));
Mat dst_gpu(imgHeight, imgWidth, CV_8UC1, Scalar(0));
//调用sobel_cpu处理图像
sobel_cpu(gaussImg, dst_cpu, imgHeight, imgWidth);
//申请指针并将它指向GPU空间
size_t num = imgHeight * imgWidth * sizeof(unsigned char);
unsigned char* in_gpu;
unsigned char* out_gpu;
cudaMalloc((void**)&in_gpu, num);
cudaMalloc((void**)&out_gpu, num);
//定义grid和block的维度(形状)
dim3 threadsPerBlock(32, 32);
dim3 blocksPerGrid((imgWidth + threadsPerBlock.x - 1) / threadsPerBlock.x,
(imgHeight + threadsPerBlock.y - 1) / threadsPerBlock.y);
//将数据从CPU传输到GPU
cudaMemcpy(in_gpu, img.data, num, cudaMemcpyHostToDevice);
//调用在GPU上运行的核函数
sobel_gpu<<<blocksPerGrid, threadsPerBlock>>>(in_gpu, out_gpu, imgHeight, imgWidth);
//将计算结果传回CPU内存
cudaMemcpy(dst_gpu.data, out_gpu, num, cudaMemcpyDeviceToHost);
imwrite("save.png", dst_gpu);
//显示处理结果, 由于这里的Jupyter模式不支持显示图像, 所以我们就不显示了
// imshow("gpu", dst_gpu);
// imshow("cpu", dst_cpu);
// waitKey(0);
//释放GPU内存空间
cudaFree(in_gpu);
cudaFree(out_gpu);
return 0;
}
编译执行命令
nvcc sobel.cu -L /usr/lib/aarch64-linux-gnu/libopencv*.so -I /usr/include/opencv4 -o sobelpython+OpenCV图像处理(八)边缘检测_Jumping boy的博客-CSDN博客_python图像边缘检测
4.4 矩阵乘法
这里是用一维数组表示full matrix, 通过给定的行列数来转换为矩阵进行运算,用cudaMemcpy直接将数据复制到Device,直接贴代码
#include<stdio.h>
#define BLOCK_SIZE 16
void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k);
__global__ void gpu_matrix_mult(int *a,int *b, int *c, int m, int n, int k);
int main(void){
int m=100;
int n=50;
int k=113;
int *h_a, *h_b, *h_gpu, *h_cpu;
// cudaMallocHost((void**)&h_a,sizeof(int)*m*n);
// cudaMallocHost((void**)&h_b,sizeof(int)*n*k);
// cudaMallocHost((void**)&h_gpu,sizeof(int)*m*k);
// cudaMallocHost((void**)&h_cpu,sizeof(int)*m*k);
h_a=(int *)malloc(sizeof(int)*m*n);
h_b=(int *)malloc(sizeof(int)*n*k);
h_cpu=(int *)malloc(sizeof(int)*m*k);
h_gpu=(int *)malloc(sizeof(int)*m*k);
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
int *d_a, *d_b, *d_gpu;
cudaMalloc((void **) &d_a, sizeof(int)*m*n);
cudaMalloc((void **) &d_b, sizeof(int)*n*k);
cudaMalloc((void **) &d_gpu, sizeof(int)*m*k);
cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice);
unsigned int grid_rows = (m+BLOCK_SIZE-1)/BLOCK_SIZE;
unsigned int grid_cols = (k+BLOCK_SIZE-1)/BLOCK_SIZE;
dim3 dimGrid(grid_rows,grid_cols);
dim3 dimBlock(BLOCK_SIZE,BLOCK_SIZE);
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_gpu, m, n, k);
cudaMemcpy(h_gpu, d_gpu, sizeof(int)*m*k, cudaMemcpyDeviceToHost);
cpu_matrix_mult(h_a, h_b, h_cpu, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i){
for (int j = 0; j < k; ++j){
if(fabs(h_cpu[i*k + j] - h_gpu[i*k + j])>(1.0e-10)){
ok = 0;
}
}
}
if(ok){
printf("Pass!!!\n");
}else{
printf("Error!!!\n");
}
// free memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_gpu);
free(h_a);
free(h_b);
free(h_gpu);
free(h_cpu);
/*
cudaFreeHost(h_a);
cudaFreeHost(h_b);
cudaFreeHost(h_gpu);
cudaFreeHost(h_cpu);
*/
return 0;
}
void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
int tmp = 0.0;
for (int h = 0; h < n; ++h)
{
tmp += h_a[i * n + h] * h_b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
__global__ void gpu_matrix_mult(int*a, int *b, int *c,int m,int n,int k){
int row=blockIdx.x*blockDim.x+threadIdx.x;
int col=blockIdx.y*blockDim.y+threadIdx.y;
int sum=0;
if(col<k&&row<m){
for(int i=0;i<n;i++){
sum+=a[row*n+i]*b[i*k+col];
}
c[row*k+col]=sum;
}
}4.5 图像转化成灰度图
4.5.1灰度图像算法
彩色图像转化为灰度图像共有三种常用的方法:
-
直接取R, B, G三个分量中数值最大的分量的数值。(0视为最小,255视为最大)。
-
取R, B, G三个分量中数值的均值
-
根据人眼对于R, B, G三种颜色的敏感度,按照一定的权值进行加权平均得到。
$$
I(x,y)=0.3\times I_R(x,y)+0.59\times I_G(x,y)+0.11\times I_B(x,y)
$$
4.5.2代码
#include <iostream>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
//将RGB图像转化成灰度图
// out = 0.3 * R + 0.59 * G + 0.11 * B
__global__ void im2gray(uchar3* in, unsigned char* out, int height, int width) {
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
if (x < width && y < height) {
uchar3 rgb = in[y * width + x];
out[y * width + x] = 0.30f * rgb.x + 0.59f * rgb.y + 0.11f * rgb.z;
}
}
int main() {
Mat src = imread("1.jpg");
uchar3* d_in;
unsigned char* d_out;
int height = src.rows;
int width = src.cols;
Mat grayImg(height, width, CV_8UC1, Scalar(0));
cudaMalloc((void**)&d_in, height * width * sizeof(uchar3));
cudaMalloc((void**)&d_out, height * width * sizeof(unsigned char));
cudaMemcpy(d_in, src.data, height * width * sizeof(uchar3), cudaMemcpyHostToDevice);
dim3 threadsPerBlock(32, 32);
dim3 blocksPerGrid((width + threadsPerBlock.x - 1) / threadsPerBlock.x, (height + threadsPerBlock.y - 1) / threadsPerBlock.y);
im2gray<<<blocksPerGrid, threadsPerBlock>>>(d_in, d_out, height, width);
cudaMemcpy(grayImg.data, d_out, height * width * sizeof(unsigned char), cudaMemcpyDeviceToHost);
imwrite("save.png", grayImg);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}五、错误检测,事件及存储单元
5.1 Cuda编程模型中的错误检测
可以查看Cuda error的四个函数:
__host____device__const char* cudaGetErrorName ( cudaError_t error )
Returns the string representation of an error code enum name.
__host____device__const char* cudaGetErrorString ( cudaError_t error )
Returns the description string for an error code.
__host____device__cudaError_t cudaGetLastError ( void )
Returns the last error from a runtime call.
__host____device__cudaError_t cudaPeekAtLastError ( void )
Returns the last error from a runtime call. 前者取回保存的错误代码,然后reset掉它,后者取回,同时持续保留这个错误代码。前者等于
result = __hidden_error_code;
__hidden_error_code = GOOD;后者等于:
result = __hidden_error_code;这里我们采用第二个,并将其封装在error.cuh文件中:
/*
Copyright 2017 Zheyong Fan, Ville Vierimaa, Mikko Ervasti, and Ari Harju
This file is part of GPUMD.
GPUMD is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
GPUMD is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with GPUMD. If not, see <http://www.gnu.org/licenses/>.
*/
#pragma once
#include <stdio.h>
//#define STRONG_DEBUG // never use it for production run; too slow
#define CHECK(call) \
do { \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) { \
fprintf(stderr, "CUDA Error:\n"); \
fprintf(stderr, " File: %s\n", __FILE__); \
fprintf(stderr, " Line: %d\n", __LINE__); \
fprintf(stderr, " Error code: %d\n", error_code); \
fprintf(stderr, " Error text: %s\n", cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)
#define PRINT_SCANF_ERROR(count, n, text) \
do { \
if (count != n) { \
fprintf(stderr, "Input Error:\n"); \
fprintf(stderr, " File: %s\n", __FILE__); \
fprintf(stderr, " Line: %d\n", __LINE__); \
fprintf(stderr, " Error text: %s\n", text); \
exit(1); \
} \
} while (0)
#define PRINT_INPUT_ERROR(text) \
do { \
fprintf(stderr, "Input Error:\n"); \
fprintf(stderr, " File: %s\n", __FILE__); \
fprintf(stderr, " Line: %d\n", __LINE__); \
fprintf(stderr, " Error text: %s\n", text); \
exit(1); \
} while (0)
#define PRINT_KEYWORD_ERROR(keyword) \
do { \
fprintf(stderr, "Input Error:\n"); \
fprintf(stderr, " File: %s\n", __FILE__); \
fprintf(stderr, " Line: %d\n", __LINE__); \
fprintf(stderr, " Error text: '%s' is an invalid keyword.\n", keyword); \
exit(1); \
} while (0)
#ifdef STRONG_DEBUG
#define CUDA_CHECK_KERNEL \
{ \
CHECK(cudaGetLastError()); \
CHECK(cudaDeviceSynchronize()); \
}
#else
#define CUDA_CHECK_KERNEL \
{ \
CHECK(cudaGetLastError()); \
}
#endif
void print_line_1(void);
void print_line_2(void);
FILE* my_fopen(const char* filename, const char* mode);do {....} while(0) 是常见的定义临时变量,防止命名冲突的做法。只是用了do...while的语法,从而能够随时定义可能重名的变量(例如你的多个CHECK都展开出来了error_code变量),同时还方便规避goto进行control flow(这里没用到)。
GPUMD/error.cuh at master · brucefan1983/GPUMD · GitHub
那么我们就可以在代码中这么使用:
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice));在这里__FILE__和__LINE__来自于C99标准,内置宏。代表了当前的源代码的文件名,还有行号。
5.2 CUDA编程模型中的事件。
事件的本质就是一个标记,它与其所在的流内的特定点相关联。可以使用时间来执行以下两个基本任务:
- 同步流执行
- 监控设备的进展
流中的任意点都可以通过API插入事件以及查询事件完成的函数,只有事件所在流中其之前的操作都完成后才能触发事件完成。默认流中设置事件,那么其前面的所有操作都完成时,事件才出发完成。 事件就像一个个路标,其本身不执行什么功能,就像我们最原始测试c语言程序的时候插入的无数多个printf一样。
创建和销毁:
声明:
cudaEvent_t event;创建:
cudaError_t cudaEventCreate(cudaEvent_t* event);销毁:
cudaError_t cudaEventDestroy(cudaEvent_t event);添加事件到当前执行流:
cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream = 0);等待事件完成,设立flag:
cudaError_t cudaEventSynchronize(cudaEvent_t event);//阻塞
cudaError_t cudaEventQuery(cudaEvent_t event);//非阻塞当然,我们也可以用它来记录执行的事件:
cudaError_t cudaEventElapsedTime(float* ms, cudaEvent_t start, cudaEvent_t stop);5.2.1使用实例
#include <stdio.h>
#include <math.h>
#include "error.cuh"
#define BLOCK_SIZE 16
__global__ void gpu_matrix_mult(int *a,int *b, int *c, int m, int n, int k)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int sum = 0;
if( col < k && row < m)
{
for(int i = 0; i < n; i++)
{
sum += a[row * n + i] * b[i * k + col];
}
c[row * k + col] = sum;
}
}
void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
int tmp = 0.0;
for (int h = 0; h < n; ++h)
{
tmp += h_a[i * n + h] * h_b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
int main(int argc, char const *argv[])
{
int m=100;
int n=100;
int k=100;
int *h_a, *h_b, *h_c, *h_cc;
CHECK(cudaMallocHost((void **) &h_a, sizeof(int)*m*n));
CHECK(cudaMallocHost((void **) &h_b, sizeof(int)*n*k));
CHECK(cudaMallocHost((void **) &h_c, sizeof(int)*m*k));
CHECK(cudaMallocHost((void **) &h_cc, sizeof(int)*m*k));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
int *d_a, *d_b, *d_c;
CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n));
CHECK(cudaMalloc((void **) &d_b, sizeof(int)*n*k));
CHECK(cudaMalloc((void **) &d_c, sizeof(int)*m*k));
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
// copy matrix A and B from host to device memory
CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice));
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
CHECK(cudaEventRecord(start));
cudaEventQuery(start);
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
CHECK(cudaMemcpy(h_c, d_c, (sizeof(int)*m*k), cudaMemcpyDeviceToHost));
//cudaThreadSynchronize();
cpu_matrix_mult(h_a, h_b, h_cc, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cc[i*k + j] - h_c[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory
CHECK(cudaFree(d_a));
CHECK(cudaFree(d_b));
CHECK(cudaFree(d_c));
CHECK(cudaFreeHost(h_a));
CHECK(cudaFreeHost(h_b));
CHECK(cudaFreeHost(h_c));
return 0;
}5.3 CUDA中的各种存储单元的使用方法

Registers
寄存器是GPU中最快的memory,kernel中没有什么特殊声明的自动变量都是放在寄存器中的。当数组的索引是constant类型且在编译期能被确定的话,就是内置类型,数组也是放在寄存器中。
- 寄存器变量是每个线程私有的,一旦thread执行结束,寄存器变量就会失效。
- 不同结构,数量不同。
Shared Memory
用__shared__修饰符修饰的变量存放在shared memory中。Shared Memory位于GPU芯片上,访问延迟仅次于寄存器。Shared Memory是可以被一个Block中的所有Thread来进行访问的,可以实现Block内的线程间的低开销通信。在SMX中,L1 Cache跟Shared Memory是共享一个64KB的高速存储单元的,他们之间的大小划分,不同的GPU结构不太一样;
- 要使用__syncthread()同步;
- 比较小,要节省着使用,不然会限制活动warp的数量。
Local Memory
Local Memory本身在硬件中没有特定的存储单元,而是从Global Memory虚拟出来的地址空间。Local Memory是为寄存器无法满足存储需求的情况而设计的,主要是用于存放单线程的大型数组和变量。Local Memory是线程私有的,线程之间是不可见的。由于GPU硬件单位没有Local Memory的存储单元,所以,针对它的访问是比较慢的,跟Global Memory的访问速度是接近的。
在以下情况使用Local Memory:
- 无法确定其索引是否为常量的数组;
- 会消耗太多寄存器空间的大型结构或数组;
- 如果内核使用了多于寄存器的任何变量(这也称为寄存器溢出);
- --ptxas-options=-v
Constant Memory
固定内存空间驻留在设备内存中,并缓存在固定缓存中(constant cache)
- constant的范围是全局的,针对所有kernel;
- kernel只能从constant Memory中读取数据,因此其初始化必须在host端使用下面的function调用:cudaError_t cudaMemcpyToSymbol(const void symbol,const void src,size_t count);
- 当一个warp中所有线程都从同一个Memory地址读取数据时,constant Memory表现会非常好,会触发广播机制。
Global Memory
Global Memory在某种意义上等同于GPU显存,kernel函数通过Global Memory来读写显存。Global Memory是kernel函数输入数据和写入结果的唯一来源。
Texture Memory
Texture Memory是GPU的重要特性之一,也是GPU编程优化的关键。Texture Memory实际上也是Global Memory的一部分,但是它有自己专用的只读cache。这个cache在浮点运算很有用,Texture Memory是针对2D空间局部性的优化策略,所以thread要获取2D数据就可以使用texture Memory来达到很高的性能。从读取性能的角度跟Constant Memory类似。
Host Memory
主机端存储器主要是内存可以分为两类:可分页内存(Pageable)和页面 (Page-Locked 或 Pinned)内存。
可分页内存通过操作系统 API(malloc/free) 分配存储器空间,该内存是可以换页的,即内存页可以被置换到磁盘中。可分页内存是不可用使用DMA(Direct Memory Acess)来进行访问的,普通的C程序使用的内存就是这个内存。
5.4 利用Shared Memory优化程序
5.4.1 Shared Memory详细介绍
Shared Memory是目前最快的可以让多个线程沟通的地方。那么,就有可能出现同时有很多线程访问Shared Memory上的数据。为了克服这个同时访问的瓶颈,Shared Memory被分成32个逻辑块(banks)。

常用的两个场景:
① 用于两个线程之间的数据交换;
② 用于线程需要多次从Global Memory中读取的数据。

5.4.2 申请共享内存
前面对比了共享内存和全局内存的访问速度,为了进一步提高访存速度,可以把全局内存一部分数据拷贝到共享内存中(由于共享内存的大小有限,大概只有几十K,所以只能分多次拷贝数据)
申请共享内存的方式分为静态申请和动态申请
申请共享内存关键字:__ shared __
块内共享内存同步:__syncthreads()函数(块内不同线程之间同步)
-
静态申请
__global__ void staticFun(int* d, int n) { __shared__ int s[64]; //静态申请,需要指定申请内存的大小 int t = treadIdx.x; s[t] = d[t]; //将全局内存数据拷贝到申请的共享内存中,之后利用共享内存中的数据参与运算将会比调 //用全局内存数据参与运算快(由于共享内存有限,不能全部拷贝到共享内存,这其中就涉及到分批拷贝问题了) __syncthreads();//需要等所有线程块都拷贝完成后再进行计算 } staticFun<<1,n>>(d, n); -
动态申请
__global__ void dynamicFun(int *d, int n) { extern __shared__ int s[]; //动态申请,不需要指定大小,需要加上extern关键字 int t = threadIdx.x; s[t] = d[t]; __syncthreads(); } dynamicFun<<1, n, n*sizeof(int)>>(d, n); //动态申请需要在外部指定共享内存大小
5.4.3 Bank Conflict
为了获得高带宽,shared Memory被分成32(对应warp中的thread)个相等大小的内存块,他们可以被同时访问。如果warp访问shared Memory,对于每个bank只访问不多于一个内存地址,那么只需要一次内存传输就可以了,否则需要多次传输,因此会降低内存带宽的使用。
当多个地址请求落在同一个bank中就会发生bank conflict,从而导致请求多次执行。硬件会把这类请求分散到尽可能多的没有conflict的那些传输操作 里面,降低有效带宽的因素是被分散到的传输操作个数。
warp有三种典型的获取shared memory的模式:
· Parallel access:多个地址分散在多个bank。
· Serial access:多个地址落在同一个bank。
· Broadcast access:一个地址读操作落在一个bank。
Parallel access是最通常的模式,这个模式一般暗示,一些(也可能是全部)地址请求能够被一次传输解决。理想情况是,获取无conflict的shared memory的时,每个地址都在落在不同的bank中。
Serial access是最坏的模式,如果warp中的32个thread都访问了同一个bank中的不同位置,那就是32次单独的请求,而不是同时访问了。
Broadcast access也是只执行一次传输,然后传输结果会广播给所有发出请求的thread。这样的话就会导致带宽利用率低。

上图是没有bank conflict,为同一个warp中的不同线程分配不同bank中的内存。
此时,为每个线程的分配内存地址为[threadIdx.y][threadIdx.x]。之所以这样,是因为同一个warp中线程是连续的,后一个线程相比前一个线程,他们的row不变,col加1(row对应着y,col对应着x)。一个技巧[x][y],x变得慢,y变得快,谁在左边谁变得慢。
如果我们写作[threadIdx.x][threadIdx.y],就是下面这种情况:
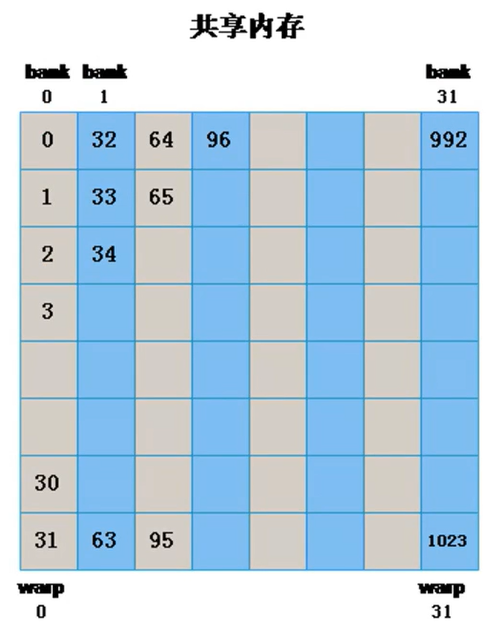
如果出现这种情况(比如矩阵转置),如何解决这个问题呢?
我们改为sData[BLOCKSIZE][BLOCKSIZE+1]即可,这样的效果就是在上图的右边再加一列:因为内存要按顺序分为32组,那么新加的第一个就是bank0的,以此类推,原来bank0的1号空间就分给了bank1。而warp中的线程不会错位,他们还是原来的位置,这样他们就分到了不同的bank里面了。

其实我们可以发现,这样新加的一列内存空间,是不会被使用到的,也就是每一个bank都浪费了一个空间。
5.5 优化矩阵乘法
5.5.1 CUDA内存读写速度比较
下列几种内存的架构参见下图:
- 线程寄存器(~1周期)
- Block共享内存(~5周期)
- Grid全局内存(~500周期)
- Grid常量内存(~5周期)
5.5.2 矩阵乘法优化
矩阵优化,是每个线程处理1个目标点(或者说,计算向量点乘),同时每个block还负责整体缓冲2个矩形的数据块,并不断滑动它(因为shared memory有限)。
首先,矩阵乘法这个问题什么地方多次读取相同数据了?
很明显,矩阵M的每一行要和矩阵N的所有列进行计算,行上面的数据被多次连续使用。
下面是一个例子:

右边是我们划分block后,每个block负责的区域。我们现在以求取紫色区域为例。
这一片紫色区域是由,M的下部分和N的右部分计算来的。
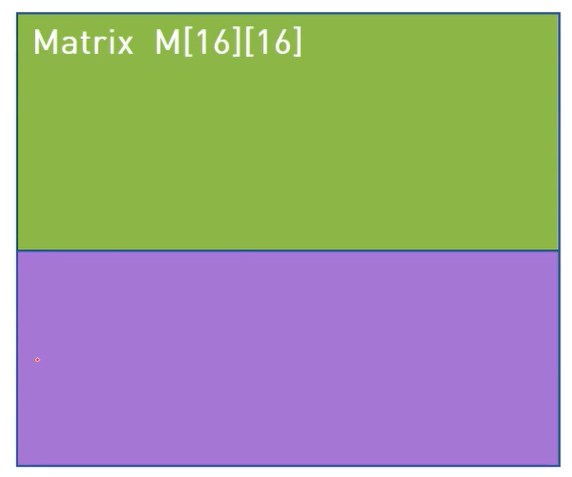
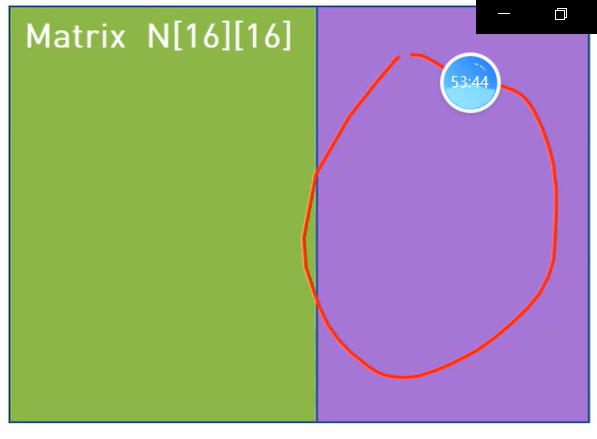
现在因为shared memory内存比较小,我们无法将MN中紫色区域全部放进来。所有我们现在把紫色区域再分成两部分,一次计算一块区域,然后将计算的两个结果相加。

CUDA实例系列一: 矩阵乘法优化_扫地的小何尚的博客-CSDN博客_cuda 例子
我们的步骤就是:
每一个线程要计算的是P中的一个点。
#include <stdio.h>
#include "error.cuh"
#define BLOCK_SIZE 16
__global__ void gpu_matrix_mult(int* a, int* b, int* c, int m, int n, int k);
__global__ void gpu_matrix_mult_shared(int* d_a, int* d_b, int* d_result, int m, int n, int k);
void cpu_matrix_mult();
int main() {
int m = 100;
int n = 133;
int k = 100;
int *h_a, *h_b, *h_gpu, *h_gpu_s, *h_cpu;
CHECK(cudaMallocHost((void**)&h_a, sizeof(int) * m * n));
CHECK(cudaMallocHost((void**)&h_b, sizeof(int) * n * k));
CHECK(cudaMallocHost((void**)&h_cpu, sizeof(int) * m * k));
CHECK(cudaMallocHost((void**)&h_gpu, sizeof(int) * m * k));
CHECK(cudaMallocHost((void**)&h_gpu_s, sizeof(int) * m * k));
cudaEvent_t start, stop, stop_share;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventCreate(&stop_share));
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < k; j++) {
h_b[i * n + j] = rand() % 1024;
}
}
int *d_a, *d_b, *d_c, *d_c_share;
CHECK(cudaMalloc((void**)&d_a, sizeof(int) * m * n));
CHECK(cudaMalloc((void**)&d_b, sizeof(int) * n * k));
CHECK(cudaMalloc((void**)&d_c, sizeof(int) * m * k));
CHECK(cudaMalloc((void**)&d_c_share, sizeof(int) * m * k));
CHECK(cudaEventRecord(start));
CHECK(cudaMemcpy(d_a, h_a, sizeof(int) * n * m, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_b, h_b, sizeof(int) * n * k, cudaMemcpyHostToDevice));
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
CHECK(cudaMemcpy(h_gpu, d_c, sizeof(int) * m * k, cudaMemcpyDeviceToHost));
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
gpu_matrix_mult_shared<<<dimGrid, dimBlock>>>(d_a, d_b, d_c_share, m, n, k);
CHECK(cudaMemcpy(h_gpu_s, d_c_share, (sizeof(int) * m * k), cudaMemcpyDeviceToHost));
CHECK(cudaEventRecord(stop_share));
CHECK(cudaEventSynchronize(stop_share));
float elapsed_time, elapsed_time_share;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
CHECK(cudaEventElapsedTime(&elapsed_time_share, stop, stop_share));
printf("Time_global = %g ms.\n", elapsed_time);
printf("Time_share = %g ms.\n", elapsed_time_share);
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
// cpu_matrix_mult(h_a, h_b, h_c, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i) {
for (int j = 0; j < k; ++j) {
if (fabs(h_gpu_s[i * k + j] - h_gpu[i * k + j]) > (1.0e-10)) {
printf("Mat4gpu_s: %d Mat4gpu: %d ", h_gpu_s[i * k + j], h_gpu[i * k + j]);
ok = 0;
}
}
}
if (ok) {
printf("Pass!!!\n");
} else {
printf("Error!!!\n");
}
// free memory
CHECK(cudaFree(d_a));
CHECK(cudaFree(d_b));
CHECK(cudaFree(d_c));
CHECK(cudaFree(d_c_share));
CHECK(cudaFreeHost(h_a));
CHECK(cudaFreeHost(h_b));
CHECK(cudaFreeHost(h_gpu));
CHECK(cudaFreeHost(h_gpu_s));
CHECK(cudaFreeHost(h_cpu));
return 0;
}
__global__ void gpu_matrix_mult(int* a, int* b, int* c, int m, int n, int k) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int sum = 0;
if (col < k && row < m) {
for (int i = 0; i < n; i++) {
sum += a[row * n + i] * b[i * k + col];
}
c[row * k + col] = sum;
}
}
void cpu_matrix_mult(int* h_a, int* h_b, int* h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i) {
for (int j = 0; j < k; ++j) {
int tmp = 0.0;
for (int h = 0; h < n; ++h) {
tmp += h_a[i * n + h] * h_b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
__global__ void gpu_matrix_mult_shared(int* d_a, int* d_b, int* d_result, int m, int n, int k) {
__shared__ int tile_a[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int tile_b[BLOCK_SIZE][BLOCK_SIZE];
int row = blockIdx.y * BLOCK_SIZE + threadIdx.y;
int col = blockIdx.x * BLOCK_SIZE + threadIdx.x;
int tmp = 0;
int idx;
for (int sub = 0; sub < (n + BLOCK_SIZE - 1) / BLOCK_SIZE; ++sub) {
idx = row * n + sub * BLOCK_SIZE + threadIdx.x;
tile_a[threadIdx.y][threadIdx.x] = row < m && (sub * BLOCK_SIZE + threadIdx.x) < n ? d_a[idx] : 0;
idx = (sub * BLOCK_SIZE + threadIdx.y) * k + col;
tile_b[threadIdx.y][threadIdx.x] = col < k && (sub * BLOCK_SIZE + threadIdx.y) < n ? d_b[idx] : 0;
__syncthreads();
for (int i = 0; i < BLOCK_SIZE; ++i) {
tmp += tile_a[threadIdx.y][i] * tile_b[i][threadIdx.x];
}
__syncthreads();
}
if (row < m && col < k) {
d_result[row * k + col] = tmp;
}
}对于上面的代码,你可能存在下面的疑惑,为什么for里面syncthreads()前面的代码只赋予了一个值为什么,后面是循环k次。要明白该函数是计算P中紫色区域的一个元素,一个block中8x8(block中的所有线程,其他block在计算P的其他区域)个线程在执行该函数的,他们每一个线程都给tile_a和tile_b赋予了一个值,在syncthreads()里面的代码,每一个线程使用到了其他线程赋予的值。
sub表示M中紫色区域被划分的份数。
5.6 矩阵转置
有一个矩阵A[M][N],求出它的转置矩阵,放到B[N][M]中。
5.6.1 实现方法
#include <stdio.h>
#include "error.cuh"
#define BLOCK_SIZE 16
__global__ void transpose1(const int* A, int* B, const int N);
__global__ void transpose2(const int* A, int* B, const int N);
__global__ void transpose3(const int* A, int* B, const int N);
__global__ void transpose4(const int* A, int* B, const int N);
int main() {
int n = 10000;
int *h_a, *h_b1, *h_b2;
CHECK(cudaMallocHost((void**)&h_a, sizeof(int) * n * n));
CHECK(cudaMallocHost((void**)&h_b1, sizeof(int) * n * n));
CHECK(cudaMallocHost((void**)&h_b2, sizeof(int) * n * n));
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
h_a[i * n + j] = rand() % 2;
}
}
int *d_a, *d_b1, *d_b2;
CHECK(cudaMalloc((void**)&d_a, sizeof(int) * n * n));
CHECK(cudaMalloc((void**)&d_b1, sizeof(int) * n * n));
CHECK(cudaMalloc((void**)&d_b2, sizeof(int) * n * n));
cudaEvent_t start, stop, stop_share;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventCreate(&stop_share));
CHECK(cudaMemcpy(d_a, h_a, sizeof(int) * n * n, cudaMemcpyHostToDevice));
unsigned int grid_rows = (n + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (n + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
CHECK(cudaEventRecord(start));
transpose1<<<dimGrid, dimBlock>>>(d_a, d_b1, n);
CHECK(cudaMemcpy(h_b1, d_b1, sizeof(int) * n * n, cudaMemcpyDeviceToHost));
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
transpose4<<<dimGrid, dimBlock>>>(d_a, d_b2, n);
CHECK(cudaMemcpy(h_b2, d_b2, sizeof(int) * n * n, cudaMemcpyDeviceToHost));
CHECK(cudaEventRecord(stop_share));
CHECK(cudaEventSynchronize(stop_share));
float elapsed_time, elapsed_time_share;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
CHECK(cudaEventElapsedTime(&elapsed_time_share, stop, stop_share));
printf("Time_global = %g ms.\n", elapsed_time);
printf("Time_share = %g ms.\n", elapsed_time_share);
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
int ok = 1;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
if (fabs(h_b1[i * n + j] - h_b2[i * n + j]) > (1.0e-10)) {
printf("Mat4gpu_s: %d Mat4gpu: %d ", h_b1[i * n + j], h_b2[i * n + j]);
ok = 0;
}
}
}
if (ok) {
printf("Pass!!!\n");
} else {
printf("Error!!!\n");
}
CHECK(cudaFree(d_a));
CHECK(cudaFree(d_b1));
CHECK(cudaFree(d_b2));
CHECK(cudaFreeHost(h_a));
CHECK(cudaFreeHost(h_b1));
CHECK(cudaFreeHost(h_b2));
return 0;
}
__global__ void transpose1(const int* A, int* B, const int N) {
const int nx = blockIdx.x * blockDim.x + threadIdx.x;
const int ny = blockIdx.y * blockDim.y + threadIdx.y;
if (nx < N && ny < N) {
B[nx * N + ny] = A[ny * N + nx];
}
}
__global__ void transpose2(const int* A, int* B, const int N) {
const int nx = blockIdx.x * blockDim.x + threadIdx.x;
const int ny = blockIdx.y * blockDim.y + threadIdx.y;
if (nx < N && ny < N) {
B[ny * N + nx] = A[nx * N + ny];
}
}
__global__ void transpose3(const int* A, int* B, const int N) {
//使用共享内存
__shared__ int S[BLOCK_SIZE][BLOCK_SIZE];
int nx1 = blockIdx.x * BLOCK_SIZE + threadIdx.x;
int ny1 = blockIdx.y * BLOCK_SIZE + threadIdx.y;
if (nx1 < N && ny1 < N) {
S[threadIdx.y][threadIdx.x] = A[ny1 * N + nx1];
}
__syncthreads();
int nx2 = blockIdx.x * BLOCK_SIZE + threadIdx.y;
int ny2 = blockIdx.y * BLOCK_SIZE + threadIdx.x;
if (nx2 < N && ny2 < N) {
B[nx2 * N + ny2] = S[threadIdx.x][threadIdx.y];
}
}
__global__ void transpose4(const int* A, int* B, const int N) {
//解决bank conflicts
__shared__ int S[BLOCK_SIZE][BLOCK_SIZE + 1];
int nx1 = blockIdx.x * BLOCK_SIZE + threadIdx.x;
int ny1 = blockIdx.y * BLOCK_SIZE + threadIdx.y;
if (nx1 < N && ny1 < N) {
S[threadIdx.y][threadIdx.x] = A[ny1 * N + nx1];
}
__syncthreads();
int nx2 = blockIdx.x * BLOCK_SIZE + threadIdx.y;
int ny2 = blockIdx.y * BLOCK_SIZE + threadIdx.x;
if (nx2 < N && ny2 < N) {
B[nx2 * N + ny2] = S[threadIdx.x][threadIdx.y];
}
}可以发现,transpose2的执行时间明显比transpose1的执行时间短。
想要了解原因,首先得了解全局内存的访问模式,有合并访问和非合并访问两种方式。若一个线程束对全局内存的一次访问导致最少的数据传输,则称该访问为合并访问,否则为非合并访问。
举个例子(假设一次数据传输指的是将32字节的数据从全局内存通过32字节的缓存传输到SM,且已知从全局内存转移到缓存的首地址一定是一个最小粒度(此处为32字节)的整数倍(比如0~31、32~63、64~95这样传),cudaMalloc分配的内存的首地址至少是256字节的整数倍),下面这两个函数,add1是合并访问的,观察其第一次传输,第一个线程块中的线程束将访问x中的第0~31个元素,总共128字节的数据大小,这样4次传输就可以完成数据搬运,而128/32=4,说明合并度为100%。而add2则是非合并访问的,观察第一次传输,第一个线程块中的线程束将访问x中的第1~32个元素,若x的首地址为256字节,则线程束将作5次传输:256~287、288~319、320~351、352~383、384~415,其合并度为4/5=80%。
//x, y, z为cudaMalloc分配全局内存的指针
void __global__ add1(float *x, float *y, float *z){
int n = threadIdx.x + blockIdx.x * blockDim.x;
z[n] = x[n] + y[n];
}
void __global__ add2(float *x, float *y, float *z){
int n = threadIdx.x+ blockIdx.x * blockDim.x + 1;
z[n] = x[n] + y[n];
}
add1<<<128, 32>>>(x, y, z);
add2<<<128, 32>>>(x, y, z);有了这个知识后,再去看矩阵转置的代码,可以发现,transpose1对矩阵A中的读取是合并的,而对矩阵B中的写入是非合并的(参见第一章多维和单维的地址转换);而transpose2对矩阵A的读取是非合并的,而对矩阵B的写入是合并的。有人便有疑惑:为何都是一次合并访问和一次非合并访问,transpose2要更快呢?个人猜测是因为GPU架构对数据读取做了优化而未对数据写入进行优化。
CUDA学习(二)矩阵转置及优化(合并访问、共享内存、bank conflict) - 知乎 (zhihu.com)
5.6.2 Bank conflicts
为了获取高带宽,共享内存在物理上被分为32个(内建变量warpsize的值)大小相同的内存bank,在每一个bank中,又可以对其中的内存地址从0开始编号。
对于bank宽度为4字节的架构(在开普勒架构中,每个bank的宽度为8字节;其他架构中bank则为4字节),共享内存是按如下方式线性地址映射到内存bank:连续的128字节的内容分摊到32分bank的某一层中,每个bank负责4字节的内容。
当同一个线程束内的多个线程试图访问同一个bank的不同层的数据时,就会发生bank冲突。下图为bank冲突示意图。
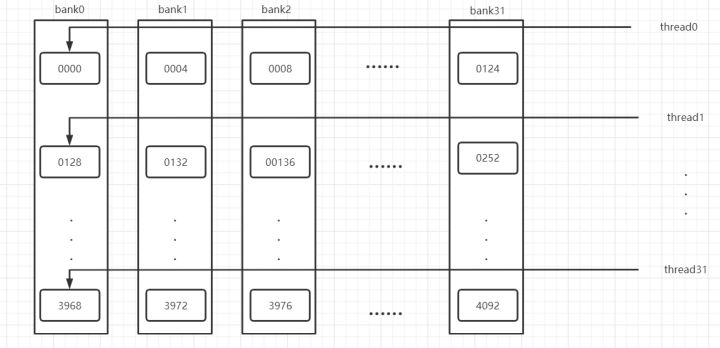
上述代码修改了共享内存的定义,就可以解决bank conflicts,这是因为改变共享内存数组大小之后,同一个线程束中的每个线程之间的地址跨度为33个字节而不是32个字节。例如,假设线程束中的第一个线程访问的是0000,则第二个线程将访问0132而不是0128,这样即可避免bank conflicts。
六、统一内存,流,原子操作
6.1 统一内存
6.6.1统一内存介绍
统一内存是 CUDA 编程模型的一个组件,在 CUDA 6.0 中首次引入,它定义了一个托管内存空间,在该空间中所有处理器都可以看到具有公共地址空间的单个连贯内存映像。
注意:处理器是指任何具有专用 MMU 的独立执行单元。这包括任何类型和架构的 CPU 和 GPU。
底层系统管理 CUDA 程序中的数据访问和位置,无需显式内存复制调用。这在两个主要方面有利于 GPU 编程:
-
通过统一系统中所有 GPU 和 CPU 的内存空间以及为 CUDA 程序员提供更紧密、更直接的语言集成,可以简化 GPU 编程。
-
通过透明地将数据迁移到使用它的处理器,可以最大限度地提高数据访问速度。
简单来说,统一内存消除了通过cudaMemcpy*()例程进行显式数据移动的需要,而不会因将所有数据放入零拷贝内存而导致性能损失。当然,数据移动仍然会发生,因此程序的运行时间通常不会减少;相反,统一内存可以编写更简单、更易于维护的代码。
统一内存提供了一个“单指针数据”模型,在概念上类似于 CUDA 的零拷贝内存。两者之间的一个关键区别在于,在零拷贝分配中,内存的物理位置固定在 CPU 系统内存中,因此程序可以快速或慢速地访问它,具体取决于访问它的位置。另一方面,统一内存将内存和执行空间解耦,以便所有数据访问都很快。
统一内存一词描述了一个为各种程序提供内存管理服务的系统,从针对运行时 API 的程序到使用虚拟 ISA (PTX) 的程序。该系统的一部分定义了选择加入统一内存服务的托管内存空间。
托管内存可与特定于设备的分配互操作和互换,例如使用 cudaMalloc() 例程创建的分配。所有在设备内存上有效的 CUDA 操作在托管内存上也有效;主要区别在于程序的主机部分也能够引用和访问内存。
注意:连接到 Tegra 的离散 GPU 不支持统一内存。
统一内存有两个基本要求:
-
具有 SM 架构 3.0 或更高版本(Kepler 类或更高版本)的 GPU
-
64 位主机应用程序和非嵌入式操作系统(Linux 或 Windows)
具有 SM 架构 6.x 或更高版本(Pascal 类或更高版本)的 GPU 提供额外的统一内存功能,例如本文档中概述的按需页面迁移和 GPU 内存超额订阅。 请注意,目前这些功能仅在 Linux 操作系统上受支持。 在 Windows 上运行的应用程序(无论是 TCC 还是 WDDM 模式)将使用基本的统一内存模型,就像在 6.x 之前的架构上一样,即使它们在具有 6.x 或更高计算能力的硬件上运行也是如
CUDA中的统一内存详解_扫地的小何尚的博客-CSDN博客_统一内存架构
6.6.2 编程
内存空间的统一意味着主机和设备之间不再需要显式内存传输。在托管内存空间中创建的任何分配都会自动迁移到需要的位置。
程序通过以下两种方式之一分配托管内存: 通过 cudaMallocManaged() 例程,它在语义上类似于 cudaMalloc();或者通过定义一个全局 managed 变量,它在语义上类似于一个 device 变量。在本文档的后面部分可以找到这些的精确定义。
注意:在具有计算能力 6.x 及更高版本的设备的支持平台上,统一内存将使应用程序能够使用默认系统分配器分配和共享数据。这允许 GPU 在不使用特殊分配器的情况下访问整个系统虚拟内存。有关更多详细信息,请参阅Programming Guide :: CUDA Toolkit Documentation (nvidia.com)
在矩阵乘法中,变量可以这样声明
__managed__ int a[1000 * 1000];
__managed__ int b[1000 * 1000];
__managed__ int c_gpu[1000 * 1000];
__managed__ int c_cpu[1000 * 1000];从而不用再main()函数中使用cudaMemcpy()
6.2 执行流 和 运行库
6.2.1.CUDA流
CUDA流表示一个GPU操作队列,该队列中的操作将以添加到流中的先后顺序而依次执行。可以将一个流看做是GPU上的一个任务,不同任务可以并行执行。
CUDA程序的典型模式:
- 输入数据从CPU主机端传输到设备端
- 在设备端执行核函数处理数据
- 处理结果传回主机端
GPU的核心数是有限的,因此同一时间能够并行运行的线程数是有限的,但是由于硬件特性,CUDA中的内存复制操作(Host to Device,Device to Host,Device to Device) 与 函数运行计算(核函数计算,主机端的计算)是相互独立的,因此可以通过流操控它们并行运算
CUDA流 表示一个GPU操作队列,其中的操作将按照指定的顺序执行
流对CUDA的加速思想就是: 将 设备执行核函数 与 设备与主机之间的数据传输 并行运行
当然,数据传输操作传输的数据是核函数下一次执行时所需的数据(处理结果传输同理)
首先,需要将数据划分为多个小块,分批进行 1. 传输到设备(H2D)、2.核函数计算(kernel)、3.传输回主机(D2H) 这三个操作。
如图所示,将要处理的数据划分为四份,使用四个流进行加速。(假设数据传输与核函数执行时间相同),在中间的几段时间三个操作是在同时运行的,

CUDA异步并发之CUDA流详解_扫地的小何尚的博客-CSDN博客_cuda异步
[CUDA编程原理] CUDA Stream - 流同步和流管理 - 简书 (jianshu.com)
CUDA 将以下操作公开为可以彼此同时操作的独立任务:
- 在主机上计算;
- 设备上的计算;
- 从主机到设备的内存传输;
- 从设备到主机的内存传输;
- 在给定设备的内存中进行内存传输;
- 设备之间的内存传输。
CUDA程序的并行层次主要有两个,一个是核函数内部的并行,一个是核函数的外部的并行。我们之前讨论的都是核函数的内部的并行。核函数外部的并行主要指:
- 核函数计算与数据传输之间的并行
- 主机计算与数据传输之间的并行
- 不同的数据传输之间的并行
- 核函数计算与主机计算之间的并行
- 不同核函数之间的并行
CUDA流表示一个GPU操作队列,该队列中的操作将以添加到流中的先后顺序而依次执行。我们的所有CUDA操作都是在流中进行的,虽然我们可能没发现,但是有我们前面的例子中的指令,内核启动,都是在CUDA流中进行的,只是这种操作是隐式的,所以肯定还有显式的,所以,流分为:
-
隐式声明的流,我们叫做空流
-
显式声明的流,我们叫做非空流
基于流的异步内核启动和数据传输支持以下类型的粗粒度并发:
- 重叠主机和设备计算
- 重叠主机计算和主机设备数据传输
- 重叠主机设备数据传输和设备计算
- 并发设备计算(多个设备)
#include <stdio.h>
#include <math.h>
#include "error.cuh"
#define N (1024*1024)
#define FULL_DATA_SIZE (N*20)
__global__ void kernel( int *a, int *b, int *c ) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
int idx1 = (idx + 1) % 256;
int idx2 = (idx + 2) % 256;
float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;
float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;
c[idx] = (as + bs) / 2;
}
}
int main( void ) {
cudaDeviceProp prop;
int whichDevice;
CHECK( cudaGetDevice( &whichDevice ) );
CHECK( cudaGetDeviceProperties( &prop, whichDevice ) );
if (!prop.deviceOverlap) {
printf( "Device will not handle overlaps, so no speed up from streams\n" );
return 0;
}
cudaEvent_t start, stop;
float elapsedTime;
cudaStream_t stream0, stream1;
int *host_a, *host_b, *host_c;
int *dev_a0, *dev_b0, *dev_c0;
int *dev_a1, *dev_b1, *dev_c1;
// start the timers
CHECK( cudaEventCreate( &start ) );
CHECK( cudaEventCreate( &stop ) );
// initialize the streams
CHECK( cudaStreamCreate( &stream0 ) );
CHECK( cudaStreamCreate( &stream1 ) );
// allocate the memory on the GPU
CHECK( cudaMalloc( (void**)&dev_a0, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_b0, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_c0, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_a1, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_b1, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_c1, N * sizeof(int) ) );
// allocate host locked memory, used to stream
CHECK( cudaHostAlloc( (void**)&host_a, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault ) );
CHECK( cudaHostAlloc( (void**)&host_b, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault ) );
CHECK( cudaHostAlloc( (void**)&host_c, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault ) );
for (int i=0; i<FULL_DATA_SIZE; i++) {
host_a[i] = rand();
host_b[i] = rand();
}
CHECK( cudaEventRecord( start, 0 ) );
// now loop over full data, in bite-sized chunks
for (int i=0; i<FULL_DATA_SIZE; i+= N*2) {
// enqueue copies of a in stream0 and stream1
CHECK( cudaMemcpyAsync( dev_a0, host_a+i, N * sizeof(int), cudaMemcpyHostToDevice, stream0 ) );
CHECK( cudaMemcpyAsync( dev_a1, host_a+i+N, N * sizeof(int), cudaMemcpyHostToDevice, stream1 ) );
// enqueue copies of b in stream0 and stream1
CHECK( cudaMemcpyAsync( dev_b0, host_b+i, N * sizeof(int), cudaMemcpyHostToDevice, stream0 ) );
CHECK( cudaMemcpyAsync( dev_b1, host_b+i+N, N * sizeof(int), cudaMemcpyHostToDevice, stream1 ) );
kernel<<<N/256,256,0,stream0>>>( dev_a0, dev_b0, dev_c0 );
kernel<<<N/256,256,0,stream1>>>( dev_a1, dev_b1, dev_c1 );
CHECK( cudaMemcpyAsync( host_c+i, dev_c0, N * sizeof(int), cudaMemcpyDeviceToHost, stream0 ) );
CHECK( cudaMemcpyAsync( host_c+i+N, dev_c1, N * sizeof(int), cudaMemcpyDeviceToHost, stream1 ) );
}
CHECK( cudaStreamSynchronize( stream0 ) );
CHECK( cudaStreamSynchronize( stream1 ) );
CHECK( cudaEventRecord( stop, 0 ) );
CHECK( cudaEventSynchronize( stop ) );
CHECK( cudaEventElapsedTime( &elapsedTime,
start, stop ) );
printf( "Time taken: %3.1f ms\n", elapsedTime );
// cleanup the streams and memory
CHECK( cudaFreeHost( host_a ) );
CHECK( cudaFreeHost( host_b ) );
CHECK( cudaFreeHost( host_c ) );
CHECK( cudaFree( dev_a0 ) );
CHECK( cudaFree( dev_b0 ) );
CHECK( cudaFree( dev_c0 ) );
CHECK( cudaFree( dev_a1 ) );
CHECK( cudaFree( dev_b1 ) );
CHECK( cudaFree( dev_c1 ) );
CHECK( cudaStreamDestroy( stream0 ) );
CHECK( cudaStreamDestroy( stream1 ) );
return 0;
}6.2.2 运行库

6.3 原子操作
6.3.1原子操作
原子函数对驻留在全局或共享内存中的一个 32 位或 64 位字执行读-修改-写原子操作。
举个例子来说, 我有很多线程. 每个线程计算出了一个结果, 我需要把所有的结果加在一起, 如下图所示.

执行到这一步时, 有很多线程想读取X的值, 并加上另一个值. 如果你在你的Kernel程序最后面直接写 x=x+a, 那么当执行到这里的时候, 一个线程在读的时候, 可能另一个线程就在写. 这会产生未定义的错误.
这时候, 你就需要原子操作来解决这个问题.
当你的一个线程使用原子加操作在这里, 另一个线程也像做原子加操作的时候, 它就会产生等待. 直到上一个操作完成. 这里会产生一个队列, one by one的执行. 如下图所示.

上面是原子加的操作示例.
1. atomicAdd()
int atomicAdd(int* address, int val);
unsigned int atomicAdd(unsigned int* address,
unsigned int val);
unsigned long long int atomicAdd(unsigned long long int* address,
unsigned long long int val);
float atomicAdd(float* address, float val);
double atomicAdd(double* address, double val);
__half2 atomicAdd(__half2 *address, __half2 val);
__half atomicAdd(__half *address, __half val);
__nv_bfloat162 atomicAdd(__nv_bfloat162 *address, __nv_bfloat162 val);
__nv_bfloat16 atomicAdd(__nv_bfloat16 *address, __nv_bfloat16 val);读取位于全局或共享内存中地址 address 的 16 位、32 位或 64 位字 old,计算 (old + val),并将结果存储回同一地址的内存中。这三个操作在一个原子事务中执行。该函数返回old。
atomicAdd() 的 32 位浮点版本仅受计算能力 2.x 及更高版本的设备支持。
atomicAdd() 的 64 位浮点版本仅受计算能力 6.x 及更高版本的设备支持。
atomicAdd() 的 32 位 __half2 浮点版本仅受计算能力 6.x 及更高版本的设备支持。 __half2 或 __nv_bfloat162 加法操作的原子性分别保证两个 __half 或 __nv_bfloat16 元素中的每一个;不保证整个 __half2 或 __nv_bfloat162 作为单个 32 位访问是原子的。
atomicAdd() 的 16 位 __half 浮点版本仅受计算能力 7.x 及更高版本的设备支持。
atomicAdd() 的 16 位 __nv_bfloat16 浮点版本仅受计算能力 8.x 及更高版本的设备支持。
2. atomicSub()
int atomicSub(int* address, int val);
unsigned int atomicSub(unsigned int* address,
unsigned int val);读取位于全局或共享内存中地址address的 32 位字 old,计算 (old - val),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
3. atomicExch()
int atomicExch(int* address, int val);
unsigned int atomicExch(unsigned int* address,
unsigned int val);
unsigned long long int atomicExch(unsigned long long int* address,
unsigned long long int val);
float atomicExch(float* address, float val);读取位于全局或共享内存中地址address的 32 位或 64 位字 old 并将 val 存储回同一地址的内存中。 这两个操作在一个原子事务中执行。 该函数返回old。
4. atomicMin()
int atomicMin(int* address, int val);
unsigned int atomicMin(unsigned int* address,
unsigned int val);
unsigned long long int atomicMin(unsigned long long int* address,
unsigned long long int val);
long long int atomicMin(long long int* address,
long long int val);读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 old 和 val 的最小值,并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicMin() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
5. atomicMax()
int atomicMax(int* address, int val);
unsigned int atomicMax(unsigned int* address,
unsigned int val);
unsigned long long int atomicMax(unsigned long long int* address,
unsigned long long int val);
long long int atomicMax(long long int* address,
long long int val);读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 old 和 val 的最大值,并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicMax() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
6. atomicInc()
unsigned int atomicInc(unsigned int* address,
unsigned int val);读取位于全局或共享内存中地址address的 32 位字 old,计算 ((old >= val) ? 0 : (old+1)),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
7. atomicDec()
unsigned int atomicDec(unsigned int* address,
unsigned int val);读取位于全局或共享内存中地址address的 32 位字 old,计算 (((old == 0) || (old > val)) ? val : (old-1) ),并将结果存储回同一个地址的内存。 这三个操作在一个原子事务中执行。 该函数返回old。
8. atomicCAS()
int atomicCAS(int* address, int compare, int val);
unsigned int atomicCAS(unsigned int* address,
unsigned int compare,
unsigned int val);
unsigned long long int atomicCAS(unsigned long long int* address,
unsigned long long int compare,
unsigned long long int val);
unsigned short int atomicCAS(unsigned short int *address,
unsigned short int compare,
unsigned short int val);读取位于全局或共享内存中地址address的 16 位、32 位或 64 位字 old,计算 (old == compare ? val : old) ,并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old(Compare And Swap)。
Bitwise Functions
9. atomicAnd()
int atomicAnd(int* address, int val);
unsigned int atomicAnd(unsigned int* address,
unsigned int val);
unsigned long long int atomicAnd(unsigned long long int* address,
unsigned long long int val);读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 (old & val),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicAnd() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
10. atomicOr()
int atomicOr(int* address, int val);
unsigned int atomicOr(unsigned int* address,
unsigned int val);
unsigned long long int atomicOr(unsigned long long int* address,
unsigned long long int val);读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 (old | val),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicOr() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
11. atomicXor()
int atomicXor(int* address, int val);
unsigned int atomicXor(unsigned int* address,
unsigned int val);
unsigned long long int atomicXor(unsigned long long int* address,
unsigned long long int val);读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 (old ^ val),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicXor() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
6.3.2 向量求和代码
和FFT思路有些一样,回头实现一个,和CPU的并行代码对比一下。
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h> //for srand()/rand()
#include <sys/time.h> //for gettimeofday()/struct timeval
#include <time.h> //for time()
#include "error.cuh"
#define N 10000000
#define BLOCK_SIZE 256
#define BLOCKS ((N + BLOCK_SIZE - 1) / BLOCK_SIZE)
__managed__ int source[N]; // input data
__managed__ int final_result[1] = {0}; // scalar output
__global__ void _sum_gpu(int* input, int count, int* output) {
__shared__ int sum_per_block[BLOCK_SIZE];
int temp = 0;
for (int idx = threadIdx.x + blockDim.x * blockIdx.x;
idx < count;
idx += gridDim.x * blockDim.x) {
temp += input[idx];
}
sum_per_block[threadIdx.x] = temp; // the per-thread partial sum is temp!
__syncthreads();
//**********shared memory summation stage***********
for (int length = BLOCK_SIZE / 2; length >= 1; length /= 2) {
int double_kill = -1;
if (threadIdx.x < length) {
double_kill = sum_per_block[threadIdx.x] + sum_per_block[threadIdx.x + length];
}
__syncthreads(); // why we need two __syncthreads() here, and,
if (threadIdx.x < length) {
sum_per_block[threadIdx.x] = double_kill;
}
__syncthreads(); //....here ?
} // the per-block partial sum is sum_per_block[0]
if (blockDim.x * blockIdx.x < count) // in case that our users are naughty
{
// the final reduction performed by atomicAdd()
if (threadIdx.x == 0)
atomicAdd(output, sum_per_block[0]);
}
}
int _sum_cpu(int* ptr, int count) {
int sum = 0;
for (int i = 0; i < count; i++) {
sum += ptr[i];
}
return sum;
}
void _init(int* ptr, int count) {
uint32_t seed = (uint32_t)time(NULL); // make huan happy
srand(seed); // reseeding the random generator
// filling the buffer with random data
for (int i = 0; i < count; i++)
ptr[i] = rand();
}
double get_time() {
struct timeval tv;
gettimeofday(&tv, NULL);
return ((double)tv.tv_usec * 0.000001 + tv.tv_sec);
}
int main() {
//**********************************
fprintf(stderr, "filling the buffer with %d elements...\n", N);
_init(source, N);
//**********************************
// Now we are going to kick start your kernel.
cudaDeviceSynchronize(); // steady! ready! go!
fprintf(stderr, "Running on GPU...\n");
double t0 = get_time();
_sum_gpu<<<BLOCKS, BLOCK_SIZE>>>(source, N, final_result);
CHECK(cudaGetLastError()); // checking for launch failures
CHECK(cudaDeviceSynchronize()); // checking for run-time failurs
double t1 = get_time();
int A = final_result[0];
fprintf(stderr, "GPU sum: %u\n", A);
//**********************************
// Now we are going to exercise your CPU...
fprintf(stderr, "Running on CPU...\n");
double t2 = get_time();
int B = _sum_cpu(source, N);
double t3 = get_time();
fprintf(stderr, "CPU sum: %u\n", B);
//******The last judgement**********
if (A == B) {
fprintf(stderr, "Test Passed!\n");
} else {
fprintf(stderr, "Test failed!\n");
exit(-1);
}
//****and some timing details*******
fprintf(stderr, "GPU time %.3f ms\n", (t1 - t0) * 1000.0);
fprintf(stderr, "CPU time %.3f ms\n", (t3 - t2) * 1000.0);
return 0;
}


0 条评论